
Introduction
In this blog post (notebook) we use the Large Language Model (LLM) prompts:
to facilitate the reading and comprehension of Stephen Wolfram’s article:
“Can AI Solve Science?”, [SW1].
Remark: We use “simple” text processing, but since the article has lots of images multi-modal models would be more appropriate.
Here is an image of article’s start:

The computations are done with Wolfram Language (WL) chatbook. The LLM functions used in the workflows are explained and demonstrated in [SW2, AA1, AA2, AAn1÷ AAn4]. The workflows are done with OpenAI’s models. Currently the models of Google’s (PaLM) and MistralAI cannot be used with the workflows below because their input token limits are too low.
Structure
The structure of the notebook is as follows:
| No | Part | Content |
|---|---|---|
| 1 | Getting the article’s text and setup | Standard ingestion and setup. |
| 2 | Article’s structure | TL;DR via a table of themes. |
| 3 | Flowcharts | Get flowcharts relating article’s concepts. |
| 4 | Extract article wisdom | Get a summary and extract ideas, quotes, references, etc. |
| 5 | Hidden messages and propaganda | Reading it with a conspiracy theorist hat on. |
Setup
Here we load a view packages and define ingestion functions:
use HTTP::Tiny;
use JSON::Fast;
use Data::Reshapers;
sub text-stats(Str:D $txt) { <chars words lines> Z=> [$txt.chars, $txt.words.elems, $txt.lines.elems] };
sub strip-html(Str $html) returns Str {
my $res = $html
.subst(/'<style'.*?'</style>'/, :g)
.subst(/'<script'.*?'</script>'/, :g)
.subst(/'<'.*?'>'/, :g)
.subst(/'<'.*?'>'/, :g)
.subst(/[\v\s*] ** 2..*/, "\n\n", :g);
return $res;
}
&strip-html
Ingest text
Here we get the plain text of the article:
my $htmlArticleOrig = HTTP::Tiny.get("https://writings.stephenwolfram.com/2024/03/can-ai-solve-science/")<content>.decode;
text-stats($htmlArticleOrig);
# (chars => 216219 words => 19867 lines => 1419)
Here we strip the HTML code from the article:
my $txtArticleOrig = strip-html($htmlArticleOrig);
text-stats($txtArticleOrig);
# (chars => 100657 words => 16117 lines => 470)
Here we clean article’s text :
my $txtArticle = $txtArticleOrig.substr(0, $txtArticleOrig.index("Posted in:"));
text-stats($txtArticle);
# (chars => 98011 words => 15840 lines => 389)
LLM access configuration
Here we configure LLM access — we use OpenAI’s model “gpt-4-turbo-preview” since it allows inputs with 128K tokens:
my $conf = llm-configuration('ChatGPT', model => 'gpt-4-turbo-preview', max-tokens => 4096, temperature => 0.7);
$conf.Hash.elems
# 22
Themes
Here we extract the themes found in the article and tabulate them (using the prompt “ThemeTableJSON”):
my $tblThemes = llm-synthesize(llm-prompt("ThemeTableJSON")($txtArticle, "article", 50), e => $conf, form => sub-parser('JSON'):drop);
$tblThemes.&dimensions;
# (12 2)
#% html
$tblThemes ==> data-translation(field-names=><theme content>)
| theme | content |
|---|---|
| Introduction to AI in Science | Discusses the potential of AI in solving scientific questions and the belief in AI’s eventual capability to do everything, including science. |
| AI’s Role and Limitations | Explores deeper questions about AI in science, its role as a practical tool or a fundamentally new method, and its limitations due to computational irreducibility. |
| AI Predictive Capabilities | Examines AI’s ability to predict outcomes and its reliance on machine learning and neural networks, highlighting limitations in predicting computational processes. |
| AI in Identifying Computational Reducibility | Discusses how AI can assist in identifying pockets of computational reducibility within the broader context of computational irreducibility. |
| AI’s Application Beyond Human Tasks | Considers if AI can understand and predict natural processes directly, beyond emulating human intelligence or tasks. |
| Solving Equations with AI | Explores the potential of AI in solving equations, particularly in areas where traditional methods are impractical or insufficient. |
| AI for Multicomputation | Discusses AI’s ability to navigate multiway systems and its potential in finding paths or solutions in complex computational spaces. |
| Exploring Systems with AI | Looks at how AI can assist in exploring spaces of systems, identifying rules or systems that exhibit specific desired characteristics. |
| Science as Narrative | Explores the idea of science providing a human-accessible narrative for natural phenomena and how AI might generate or contribute to scientific narratives. |
| Finding What’s Interesting | Discusses the challenge of determining what’s interesting in science and how AI might assist in identifying interesting phenomena or directions. |
| Beyond Exact Sciences | Explores the potential of AI in extending the domain of exact sciences to include more subjective or less formalized areas of knowledge. |
| Conclusion | Summarizes the potential and limitations of AI in science, emphasizing the combination of AI with computational paradigms for advancing science. |
Remark: A fair amount of LLMs give their code results within Markdown code block delimiters (like ““`”.) Hence, (1) the (WL-specified) prompt “ThemeTableJSON” does not use Interpreter["JSON"], but Interpreter["String"], and (2) we use above the sub-parser ‘JSON’ with dropping of non-JSON strings in order to convert the LLM output into a Raku data structure.
Flowcharts
In this section we LLMs to get Mermaid-JS flowcharts that correspond to the content of [SW1].
Remark: Below in order to display Mermaid-JS diagrams we use both the package “WWW::MermaidInk”, [AAp7], and the dedicated mermaid magic cell of Raku Chatabook, [AA6].
Big picture concepts
Here we generate Mermaid-JS flowchart for the “big picture” concepts:
my $mmdBigPicture =
llm-synthesize([
"Create a concise mermaid-js graph for the connections between the big concepts in the article:\n\n",
$txtArticle,
llm-prompt("NothingElse")("correct mermaid-js")
], e => $conf)
Here we define “big picture” styling theme:
my $mmdBigPictureTheme = q:to/END/;
%%{init: {'theme': 'neutral'}}%%
END
Here we create the flowchart from LLM’s specification:
mermaid-ink($mmdBigPictureTheme.chomp ~ $mmdBigPicture.subst(/ '```mermaid' | '```'/, :g), background => 'Cornsilk', format => 'svg')
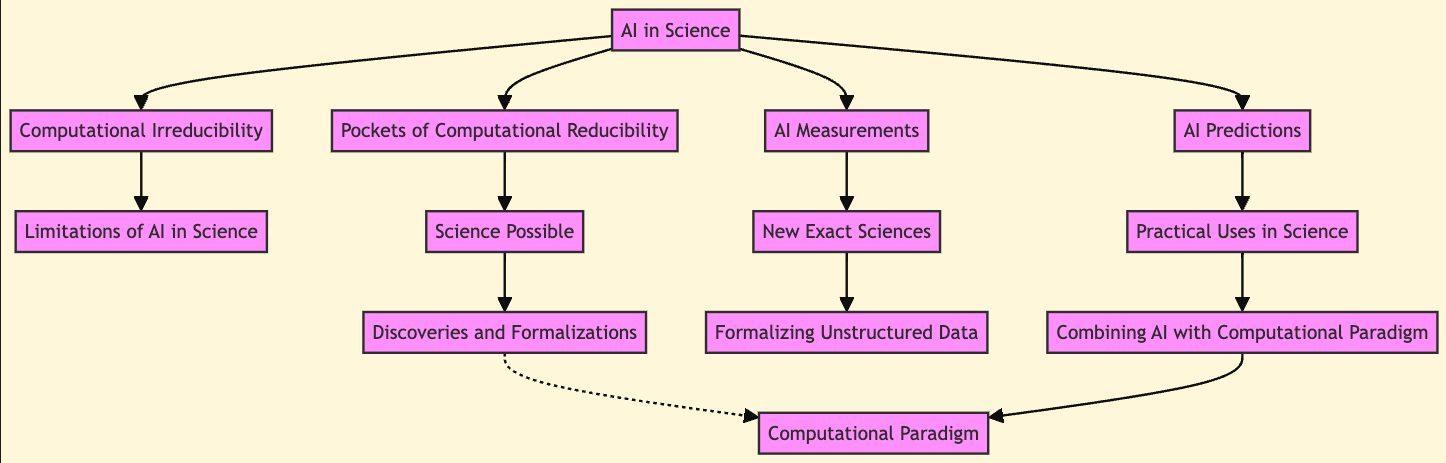
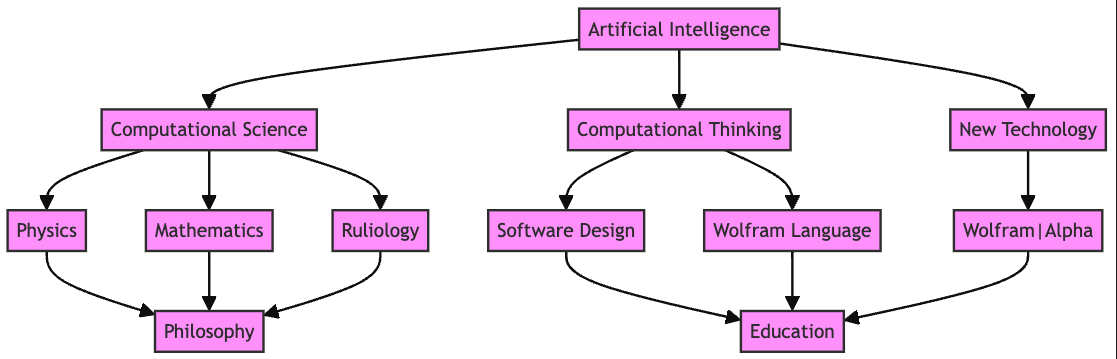
We made several “big picture” flowchart generations. Here is the result of another attempt:
#% mermaid
graph TD;
AI[Artificial Intelligence] --> CompSci[Computational Science]
AI --> CompThink[Computational Thinking]
AI --> NewTech[New Technology]
CompSci --> Physics
CompSci --> Math[Mathematics]
CompSci --> Ruliology
CompThink --> SoftwareDesign[Software Design]
CompThink --> WolframLang[Wolfram Language]
NewTech --> WolframAlpha["Wolfram|Alpha"]
Physics --> Philosophy
Math --> Philosophy
Ruliology --> Philosophy
SoftwareDesign --> Education
WolframLang --> Education
WolframAlpha --> Education
%% Styling
classDef default fill:#8B0000,stroke:#333,stroke-width:2px;
Fine grained
Here we derive a flowchart that refers to more detailed, finer grained concepts:
my $mmdFineGrained =
llm-synthesize([
"Create a mermaid-js flowchart with multiple blocks and multiple connections for the relationships between concepts in the article:\n\n",
$txtArticle,
"Use the concepts in the JSON table:",
$tblThemes,
llm-prompt("NothingElse")("correct mermaid-js")
], e => $conf)
Here we define “fine grained” styling theme:
my $mmdFineGrainedTheme = q:to/END/;
%%{init: {'theme': 'base','themeVariables': {'backgroundColor': '#FFF'}}}%%
END
Here we create the flowchart from LLM’s specification:
mermaid-ink($mmdFineGrainedTheme.chomp ~ $mmdFineGrained.subst(/ '```mermaid' | '```'/, :g), format => 'svg')
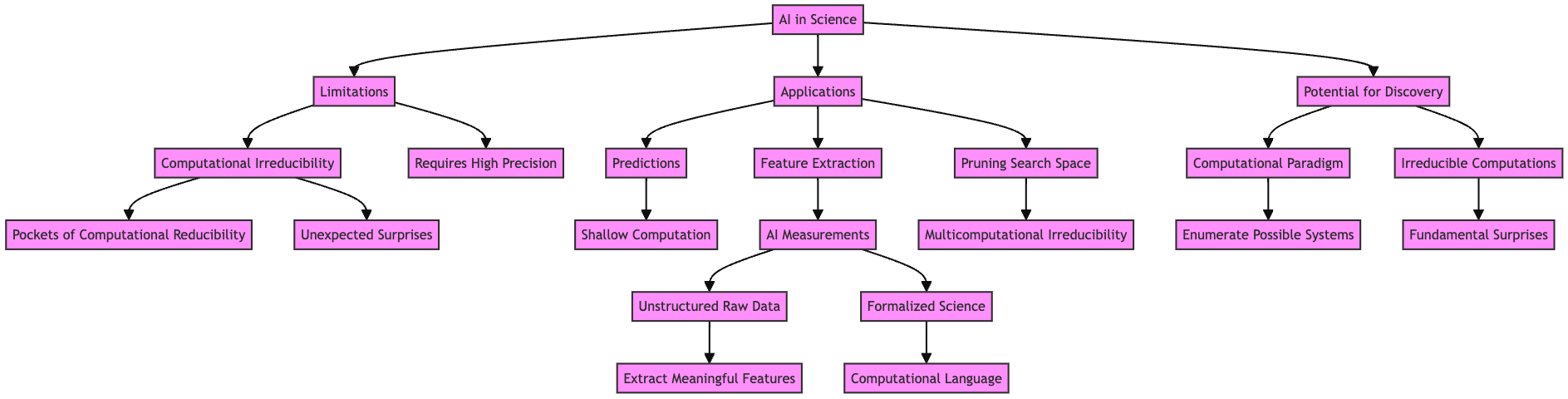
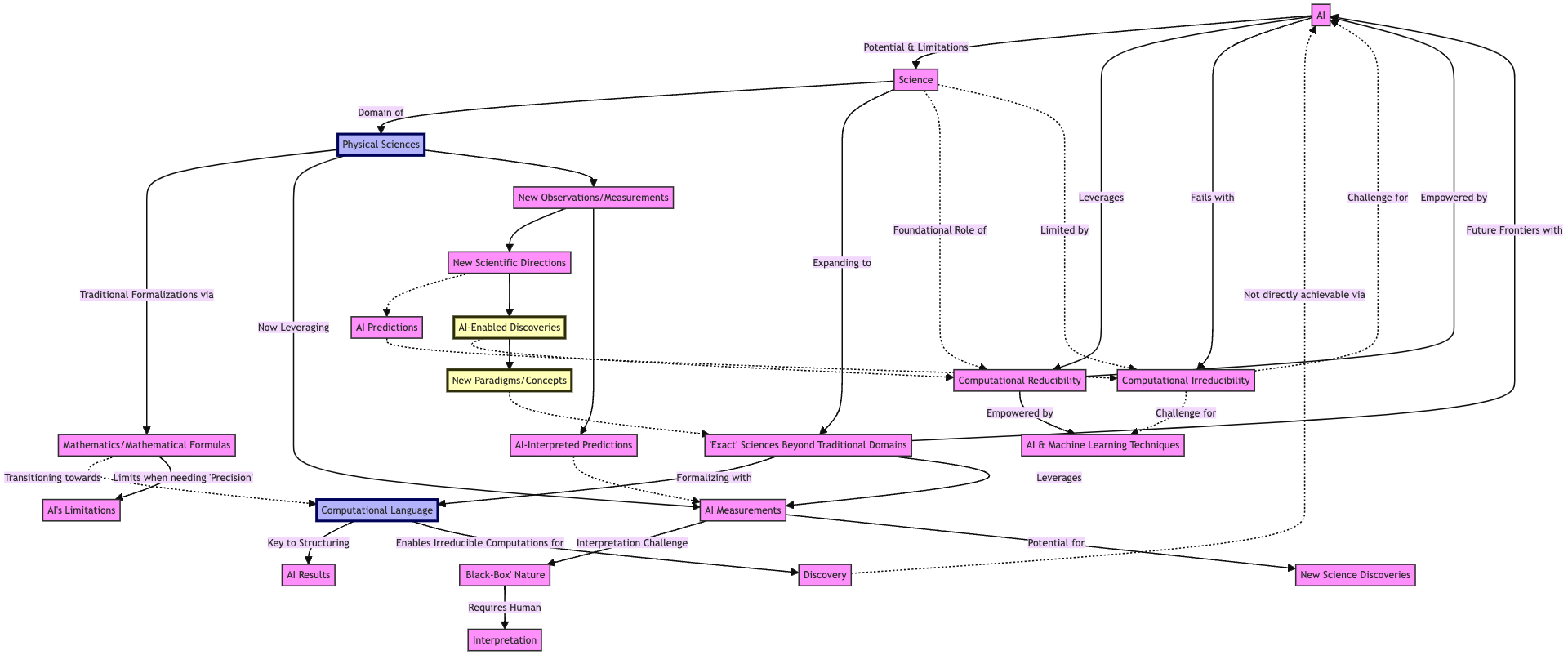
We made several “fine grained” flowchart generations. Here is the result of another attempt:
#% mermaid
graph TD
AI["AI"] -->|Potential & Limitations| Science["Science"]
AI -->|Leverages| CR["Computational Reducibility"]
AI -->|Fails with| CI["Computational Irreducibility"]
Science -->|Domain of| PS["Physical Sciences"]
Science -->|Expanding to| S["'Exact' Sciences Beyond Traditional Domains"]
Science -.->|Foundational Role of| CR
Science -.->|Limited by| CI
PS -->|Traditional Formalizations via| Math["Mathematics/Mathematical Formulas"]
PS -->|Now Leveraging| AI_Measurements["AI Measurements"]
S -->|Formalizing with| CL["Computational Language"]
S -->|Leverages| AI_Measurements
S -->|Future Frontiers with| AI
AI_Measurements -->|Interpretation Challenge| BlackBox["'Black-Box' Nature"]
AI_Measurements -->|Potential for| NewScience["New Science Discoveries"]
CL -->|Key to Structuring| AI_Results["AI Results"]
CL -->|Enables Irreducible Computations for| Discovery["Discovery"]
Math -.->|Transitioning towards| CL
Math -->|Limits when needing 'Precision'| AI_Limits["AI's Limitations"]
Discovery -.->|Not directly achievable via| AI
BlackBox -->|Requires Human| Interpretation["Interpretation"]
CR -->|Empowered by| AI & ML_Techniques["AI & Machine Learning Techniques"]
CI -.->|Challenge for| AI & ML_Techniques
PS --> Observations["New Observations/Measurements"] --> NewDirections["New Scientific Directions"]
Observations --> AI_InterpretedPredictions["AI-Interpreted Predictions"]
NewDirections -.-> AI_Predictions["AI Predictions"] -.-> CI
NewDirections --> AI_Discoveries["AI-Enabled Discoveries"] -.-> CR
AI_Discoveries --> NewParadigms["New Paradigms/Concepts"] -.-> S
AI_InterpretedPredictions -.-> AI_Measurements
%% Styling
classDef default fill:#f9f,stroke:#333,stroke-width:2px;
classDef highlight fill:#bbf,stroke:#006,stroke-width:4px;
classDef imp fill:#ffb,stroke:#330,stroke-width:4px;
class PS,CL highlight;
class AI_Discoveries,NewParadigms imp;
Summary and ideas
Here we get a summary and extract ideas, quotes, and references from the article:
my $sumIdea =llm-synthesize(llm-prompt("ExtractArticleWisdom")($txtArticle), e => $conf);
text-stats($sumIdea)
# (chars => 7386 words => 1047 lines => 78)
The result is rendered below.
#% markdown
$sumIdea.subst(/ ^^ '#' /, '###', :g)
SUMMARY
Stephen Wolfram’s writings explore the capabilities and limitations of AI in the realm of science, discussing how AI can assist in scientific discovery and understanding but also highlighting its limitations due to computational irreducibility and the need for human interpretation and creativity.
IDEAS:
- AI has made surprising successes but cannot solve all scientific problems due to computational irreducibility.
- Large Language Models (LLMs) provide a new kind of interface for scientific work, offering high-level autocomplete for scientific knowledge.
- The transition to computational representation of the world is transforming science, with AI playing a significant role in accessing and exploring this computational realm.
- AI, particularly through neural networks and machine learning, offers tools for predicting scientific outcomes, though its effectiveness is bounded by the complexity of the systems it attempts to model.
- Computational irreducibility limits the ability of AI to predict or solve all scientific phenomena, ensuring that surprises and new discoveries remain a fundamental aspect of science.
- Despite AI’s limitations, it has potential in identifying pockets of computational reducibility, streamlining the discovery of scientific knowledge.
- AI’s success in areas like visual recognition and language generation suggests potential for contributing to scientific methodologies and understanding, though its ability to directly engage with raw natural processes is less certain.
- AI techniques, including neural networks and machine learning, have shown promise in areas like solving equations and exploring multicomputational processes, but face challenges due to computational irreducibility.
- The role of AI in generating human-understandable narratives for scientific phenomena is explored, highlighting the potential for AI to assist in identifying interesting and meaningful scientific inquiries.
- The exploration of “AI measurements” opens up new possibilities for formalizing and quantifying aspects of science that have traditionally been qualitative or subjective, potentially expanding the domain of exact sciences.
QUOTES:
- “AI has the potential to give us streamlined ways to find certain kinds of pockets of computational reducibility.”
- “Computational irreducibility is what will prevent us from ever being able to completely ‘solve science’.”
- “The AI is doing ‘shallow computation’, but when there’s computational irreducibility one needs irreducible, deep computation to work out what will happen.”
- “AI measurements are potentially a much richer source of formalizable material.”
- “AI… is not something built to ‘go out into the wilds of the ruliad’, far from anything already connected to humans.”
- “Despite AI’s limitations, it has potential in identifying pockets of computational reducibility.”
- “AI techniques… have shown promise in areas like solving equations and exploring multicomputational processes.”
- “AI’s success in areas like visual recognition and language generation suggests potential for contributing to scientific methodologies.”
- “There’s no abstract notion of ‘interestingness’ that an AI or anything can ‘go out and discover’ ahead of our choices.”
- “The whole story of things like trained neural nets that we’ve discussed here is a story of leveraging computational reducibility.”
HABITS:
- Continuously exploring the capabilities and limitations of AI in scientific discovery.
- Engaging in systematic experimentation to understand how AI tools can assist in scientific processes.
- Seeking to identify and utilize pockets of computational reducibility where AI can be most effective.
- Exploring the use of neural networks and machine learning for predicting and solving scientific problems.
- Investigating the potential for AI to assist in creating human-understandable narratives for complex scientific phenomena.
- Experimenting with “AI measurements” to quantify and formalize traditionally qualitative aspects of science.
- Continuously refining and expanding computational language to better interface with AI capabilities.
- Engaging with and contributing to discussions on the role of AI in the future of science and human understanding.
- Actively seeking new methodologies and innovations in AI that could impact scientific discovery.
- Evaluating the potential for AI to identify interesting and meaningful scientific inquiries through analysis of large datasets.
FACTS:
- Computational irreducibility ensures that surprises and new discoveries remain a fundamental aspect of science.
- AI’s effectiveness in scientific modeling is bounded by the complexity of the systems it attempts to model.
- AI can identify pockets of computational reducibility, streamlining the discovery of scientific knowledge.
- Neural networks and machine learning offer tools for predicting outcomes but face challenges due to computational irreducibility.
- AI has shown promise in areas like solving equations and exploring multicomputational processes.
- The potential of AI in generating human-understandable narratives for scientific phenomena is actively being explored.
- “AI measurements” offer new possibilities for formalizing aspects of science that have been qualitative or subjective.
- The transition to computational representation of the world is transforming science, with AI playing a significant role.
- Machine learning techniques can be very useful for providing approximate answers in scientific inquiries.
- AI’s ability to directly engage with raw natural processes is less certain, despite successes in human-like tasks.
REFERENCES:
- Stephen Wolfram’s writings on AI and science.
- Large Language Models (LLMs) as tools for scientific work.
- The concept of computational irreducibility and its implications for science.
- Neural networks and machine learning techniques in scientific prediction and problem-solving.
- The role of AI in creating human-understandable narratives for scientific phenomena.
- The use of “AI measurements” in expanding the domain of exact sciences.
- The potential for AI to assist in identifying interesting and meaningful scientific inquiries.
RECOMMENDATIONS:
- Explore the use of AI and neural networks for identifying pockets of computational reducibility in scientific research.
- Investigate the potential of AI in generating human-understandable narratives for complex scientific phenomena.
- Utilize “AI measurements” to formalize and quantify traditionally qualitative aspects of science.
- Engage in systematic experimentation to understand the limitations and capabilities of AI in scientific discovery.
- Consider the role of computational irreducibility in shaping the limitations of AI in science.
- Explore the potential for AI to assist in identifying interesting and meaningful scientific inquiries.
- Continuously refine and expand computational language to better interface with AI capabilities in scientific research.
- Investigate new methodologies and innovations in AI that could impact scientific discovery.
- Consider the implications of AI’s successes in human-like tasks for its potential contributions to scientific methodologies.
- Explore the use of machine learning techniques for providing approximate answers in scientific inquiries where precision is less critical.
Hidden and propaganda messages
In this section we convince ourselves that the article is apolitical and propaganda-free.
Remark: We leave to reader as an exercise to verify that both the overt and hidden messages found by the LLM below are explicitly stated in article.
Here we find the hidden and “propaganda” messages in the article:
my $propMess =llm-synthesize([llm-prompt("FindPropagandaMessage"), $txtArticle], e => $conf);
text-stats($propMess)
# (chars => 6193 words => 878 lines => 64)
Remark: The prompt “FindPropagandaMessage” has an explicit instruction to say that it is intentionally cynical. It is also, marked as being “For fun.”
The LLM result is rendered below.
#% markdown
$propMess.subst(/ ^^ '#' /, '###', :g).subst(/ (<[A..Z \h \']>+ ':') /, { "### {$0.Str} \n"}, :g)
OVERT MESSAGE:
Stephen Wolfram evaluates the potential and limitations of AI in advancing science.
HIDDEN MESSAGE:
Despite AI’s growth, irreducible complexity limits its scientific problem-solving capacity.
HIDDEN OPINIONS:
- AI can leverage computational reducibility akin to human minds.
- Traditional mathematical methods surpass AI in solving precise equations.
- AI’s “shallow computation” struggles with computational irreducibility.
- AI can provide practical tools for science within its computational reducibility limits.
- AI’s effectiveness is contingent on approximate answers, failing at precise perfection.
- AI introduces a new, human-like method to harness computational reducibility.
- Fundamental discoveries are more likely through irreducible computations, not AI.
- Combining AI with the computational paradigm offers the best science advancement path.
- AI’s potential in science is hyped beyond its actual foundational impact.
- AI’s role in science is more about aiding existing processes than groundbreaking discoveries.
SUPPORTING ARGUMENTS and### QUOTES:
- “AI is doing ‘shallow computation’, but when there’s computational irreducibility one needs irreducible, deep computation to work out what will happen.”
- “Typical AI approach to science doesn’t involve explicitly ‘formalizing things’.”
- “In terms of fundamental potential for discovery, AI pales in comparison to what we can build from the computational paradigm.”
- “AI can be very useful if an approximate (‘80%’) answer is good enough.”
- “AI measurements seem to have a certain immediate ‘subjectivity’.”
- “AI introduces a new—and rather human-like—way of leveraging computational reducibility.”
- “AI’s effectiveness is contingent on approximate answers, failing at precise perfection.”
- “AI’s role in science is more about aiding existing processes than groundbreaking discoveries.”
- “Irreducible computations that we do offer greater potential for discovery than typical AI.”
DESIRED AUDIENCE OPINION CHANGE:
- Appreciate the limitations and strengths of AI in scientific exploration.
- Recognize the irreplaceable value of human insight in science.
- View AI as a tool, not a replacement, for traditional scientific methods.
- Embrace computational irreducibility as a barrier and boon to discovery.
- Acknowledge the need for combining AI with computational paradigms.
- Understand that AI’s role is to augment, not overshadow, human-led science.
- Realize the necessity of approximate solutions in AI-driven science.
- Foster realistic expectations from AI in making scientific breakthroughs.
- Advocate for deeper computational approaches alongside AI in science.
- Encourage interdisciplinary approaches combining AI with formal sciences.
DESIRED AUDIENCE ACTION CHANGE:
- Support research combining AI with computational paradigms.
- Encourage the use of AI for practical, approximate scientific solutions.
- Advocate for AI’s role as a supplementary tool in science.
- Push for education that integrates AI with traditional scientific methods.
- Promote the study of computational irreducibility alongside AI.
- Emphasize AI’s limitations in scientific discussions and funding.
- Inspire new approaches to scientific exploration using AI.
- Foster collaboration between AI researchers and traditional scientists.
- Encourage critical evaluation of AI’s potential in groundbreaking discoveries.
- Support initiatives that aim to combine AI with human insight in science.
MESSAGES:
Stephen Wolfram wants you to believe AI can advance science, but he’s actually saying its foundational impact is limited by computational irreducibility.
PERCEPTIONS:
Wolfram wants you to see him as optimistic about AI in science, but he’s actually cautious about its ability to make fundamental breakthroughs.
ELLUL’S ANALYSIS:
Jacques Ellul would likely interpret Wolfram’s findings as a validation of the view that technological systems, including AI, are inherently limited by the complexity of human thought and the natural world. The presence of computational irreducibility underscores the unpredictability and uncontrollability that Ellul warned technology could not tame, suggesting that even advanced AI cannot fully solve or understand all scientific problems, thus maintaining a degree of human autonomy and unpredictability in the face of technological advancement.
BERNAYS’ ANALYSIS:
Edward Bernays might view Wolfram’s exploration of AI in science through the lens of public perception and manipulation, arguing that while AI presents a new frontier for scientific exploration, its effectiveness and limitations must be communicated carefully to avoid both undue skepticism and unrealistic expectations. Bernays would likely emphasize the importance of shaping public opinion to support the use of AI as a tool that complements human capabilities rather than replacing them, ensuring that society remains engaged and supportive of AI’s role in scientific advancement.
LIPPMANN’S ANALYSIS:
Walter Lippmann would likely focus on the implications of Wolfram’s findings for the “pictures in our heads,” or public understanding of AI’s capabilities and limitations in science. Lippmann might argue that the complexity of AI and computational irreducibility necessitates expert mediation to accurately convey these concepts to the public, ensuring that society’s collective understanding of AI in science is based on informed, rather than simplistic or sensationalized, interpretations.
FRANKFURT’S ANALYSIS:
Harry G. Frankfurt might critique the discourse around AI in science as being fraught with “bullshit,” where speakers and proponents of AI might not necessarily lie about its capabilities, but could fail to pay adequate attention to the truth of computational irreducibility and the limitations it imposes. Frankfurt would likely appreciate Wolfram’s candid assessment of AI, seeing it as a necessary corrective to overly optimistic or vague claims about AI’s potential to revolutionize science.
NOTE: This AI is tuned specifically to be cynical and politically-minded. Don’t take it as perfect. Run it multiple times and/or go consume the original input to get a second opinion.
References
Articles
[AA1] Anton Antonov, “Workflows with LLM functions”, (2023), RakuForPrediction at WordPress.
[AA2] Anton Antonov, “LLM aids for processing of the first Carlson-Putin interview”, (2024), RakuForPrediction at WordPress.
[SW1] Stephen Wolfram, “Can AI Solve Science?”, (2024), Stephen Wolfram’s writings.
[SW2] Stephen Wolfram, “The New World of LLM Functions: Integrating LLM Technology into the Wolfram Language”, (2023), Stephen Wolfram’s writings.
Notebooks
[AAn1] Anton Antonov, “Workflows with LLM functions (in WL)”, (2023), Wolfram Community.
[AAn2] Anton Antonov, “LLM aids for processing of the first Carlson-Putin interview”, (2024), Wolfram Community.
[AAn3] Anton Antonov, “LLM aids for processing Putin’s State-Of-The-Nation speech given on 2/29/2024”, (2024), Wolfram Community.
[AAn4] Anton Antonov, “LLM over Trump vs. Anderson: analysis of the slip opinion of the Supreme Court of the United States”, (2024), Wolfram Community.
[AAn5] Anton Antonov, “Markdown to Mathematica converter”, (2023), Wolfram Community.
[AAn6] Anton Antonov, “Monte-Carlo demo notebook conversion via LLMs”, (2024), Wolfram Community.
Packages, repositories
[AAp1] Anton Antonov, WWW::OpenAI Raku package, (2023-2024), GitHub/antononcube.
[AAp2] Anton Antonov, WWW::PaLM Raku package, (2023-2024), GitHub/antononcube.
[AAp3] Anton Antonov, WWW::MistralAI Raku package, (2023-2024), GitHub/antononcube.
[AAp4] Anton Antonov, LLM::Functions Raku package, (2023-2024), GitHub/antononcube.
[AAp5] Anton Antonov, LLM::Prompts Raku package, (2023-2024), GitHub/antononcube.
[AAp6] Anton Antonov, Jupyter::Chatbook Raku package, (2023-2024), GitHub/antononcube.
[AAp7] Anton Antonov, WWW:::MermaidInk Raku package, (2023-2024), GitHub/antononcube.
[DMr1] Daniel Miessler, Fabric, (2024), GitHub/danielmiessler.





